Context Engineering
上下文长度(Context Length)
所有厂商提供的LLM都有上下文长度限制,不同模型的上下文长度限制可能不一样,大部分LLM都可以支持到20w~60w Token,Gemini更是支持到了100w Token。
大语言模型的”记忆”本质上是一个固定大小的文本窗口。就像人类的记忆一样,这个窗口有容量限制。当新信息进入时,旧信息就有可能被”挤出去”。
[系统提示] + [历史对话] + [当前输入] = 总上下文
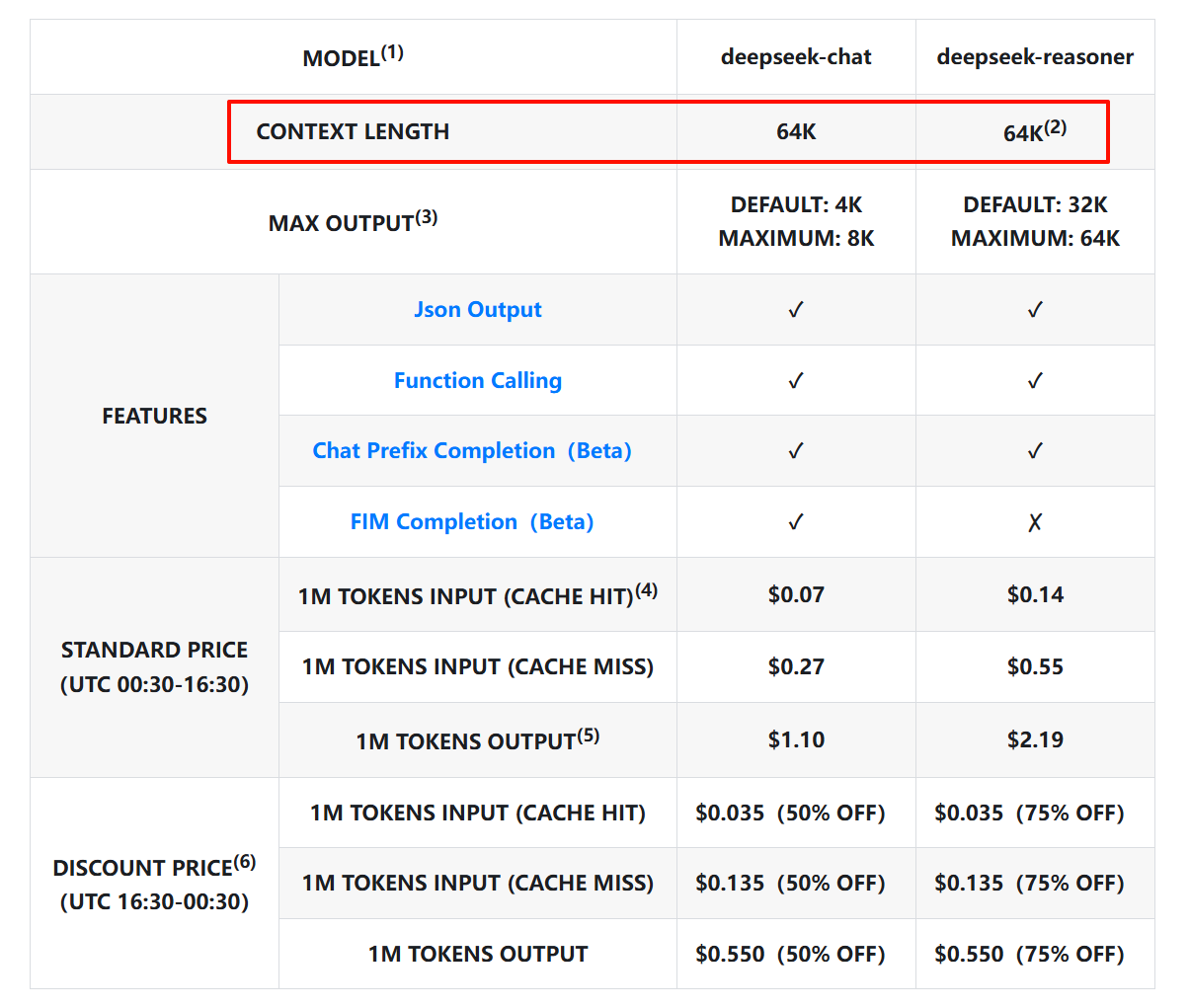
以DeepSeek为例,无论是推理模型还是对话模型,Context Window 都是 64K,如果要给 Context Window 下一个定义,那么应该是这样:
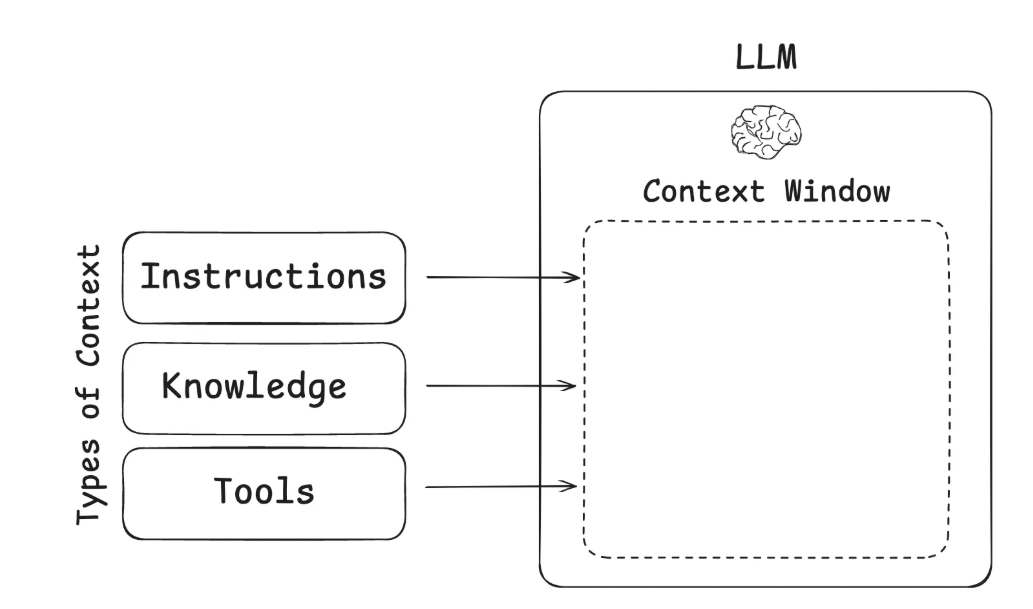
LLM 的 Context Window 指模型在单次推理过程中可处理的最大 Token 长度,也可以理解为LLM在进行一次推理时所能看到的最大上下文信息;提供更多的上下文信息,能辅助LLM更好地回答问题。
上下文窗口是模型处理单次推理的硬限制,不可突破;这里的‘单次’既可以是单轮对话,也可以是多轮对话
单轮对话的情况
例如打开一个 DeepSeek 新会话窗口时,会开启一轮新的会话,用户输入内容,模型输出推理内容。这就是一个单次推理过程。在这简单的一来一回的过程中,所有内容(输入+输出)的Tokens总和不能超过 64K(约 6 万多字)。
DeepSeek V3模型最大输出长度为 8K,那么输入内容的上限就是:64K- 8K = 56K。在一次性问答中,最多可以输入 5 万多字,模型最多输出 8 千多字。
多轮对话的情况
多轮对话实际上是在历史对话记录(输入+输出)后面拼接上最新的输入,然后一起提交给大模型,模型根据历史对话和最新的提问产生最新输出内容。
DeepSeek /chat/completions API 是一个“无状态” API,即服务端不记录用户请求的上下文,用户在每次请求时,需将之前所有对话历史拼接好后,传递给对话 API。——出自deepseek官方文档
在多轮对话的情况下,并不是每一轮对话的 Context Window 都是 64K,而是随着对话轮次的增多 Context Window 越来越小。比如第一轮对话的输入+输出使用了 32K,那么第二轮就只剩下 32K 了,原理就像单轮对话分析的那样。
上下文截断
如果每轮对话的输入+输出都很长,那么是不是用不了几轮就超过模型限制无法使用了?实际上还能正常使用!无论对话多少轮,模型都能响应并输出内容。
在使用基于大模型的产品时(如 DeepSeek、Qwen等),服务提供商不会让用户直接面对硬性的上下文窗口限制,而是通过 “上下文截断” 策略实现“超长文本处理”。例如模型原生支持 64K,但用户累计输入+输出已达 64K ,当用户再进行一次请求(比如输入有 2K)时就超限了,这时候服务端仅保留最后 64K Tokens 供模型参考,初始的前 2K Token被丢弃(可能是输入内容,也可能包含LLM的响应内容)。对用户来说,最后输入的内容被保留了下来,最早的输入(or输出)被丢弃了。这就是为什么在进行多轮对话时,虽然还是能够得到正常响应,但大模型可能会产生 “失忆” 的状况。Context Window 总量就那么多,超出范围之后LLM记不住所有东西,只能选择记住后面的忘记前面的。
在模型架构层面,上下文窗口是硬性约束,由以下因素决定:
- 位置编码的范围:Transformer 模型通过位置编码(如 RoPE、ALiBi)为每个 token 分配位置信息,其设计范围直接限制模型能处理的最大序列长度。
- 自注意力机制的计算方式:生成每个新 token 时,模型需计算其与所有历史 token(输入+已生成输出) 的注意力权重,因此总序列长度严格受限。KV Cache 的显存占用与总序列长度成正比,超过窗口会导致显存溢出或计算错误。
什么是“上下文”?
如果把LLM看做CPU,Context就像是RAM。RAM的存储空间是有限的,LLM 处理各种上下文的能力也是有限的,所有大模型都有上下文窗口限制。正如操作系统会精心管理哪些内容可以放入 CPU 的 RAM 中一样,可以认为“Context Engineering”也扮演着类似的角色,如何让LLM在有限的”记忆空间”中始终关注最重要的信息,并在每一次对话中把精心挑选的最重要的信息传递给大模型,这就是Context Engineering要解决的根本问题。
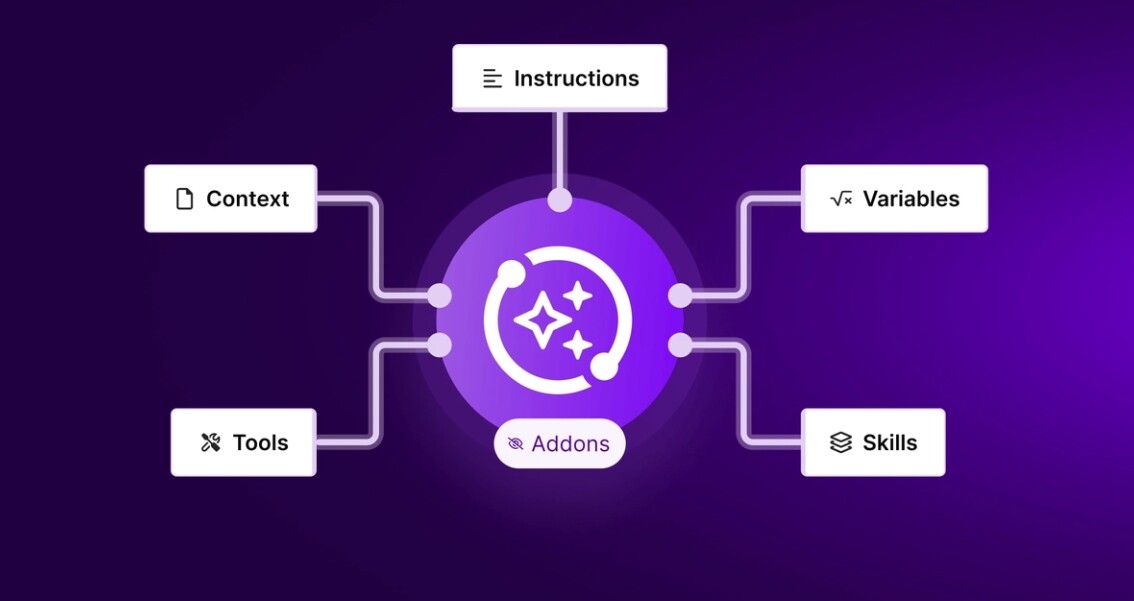
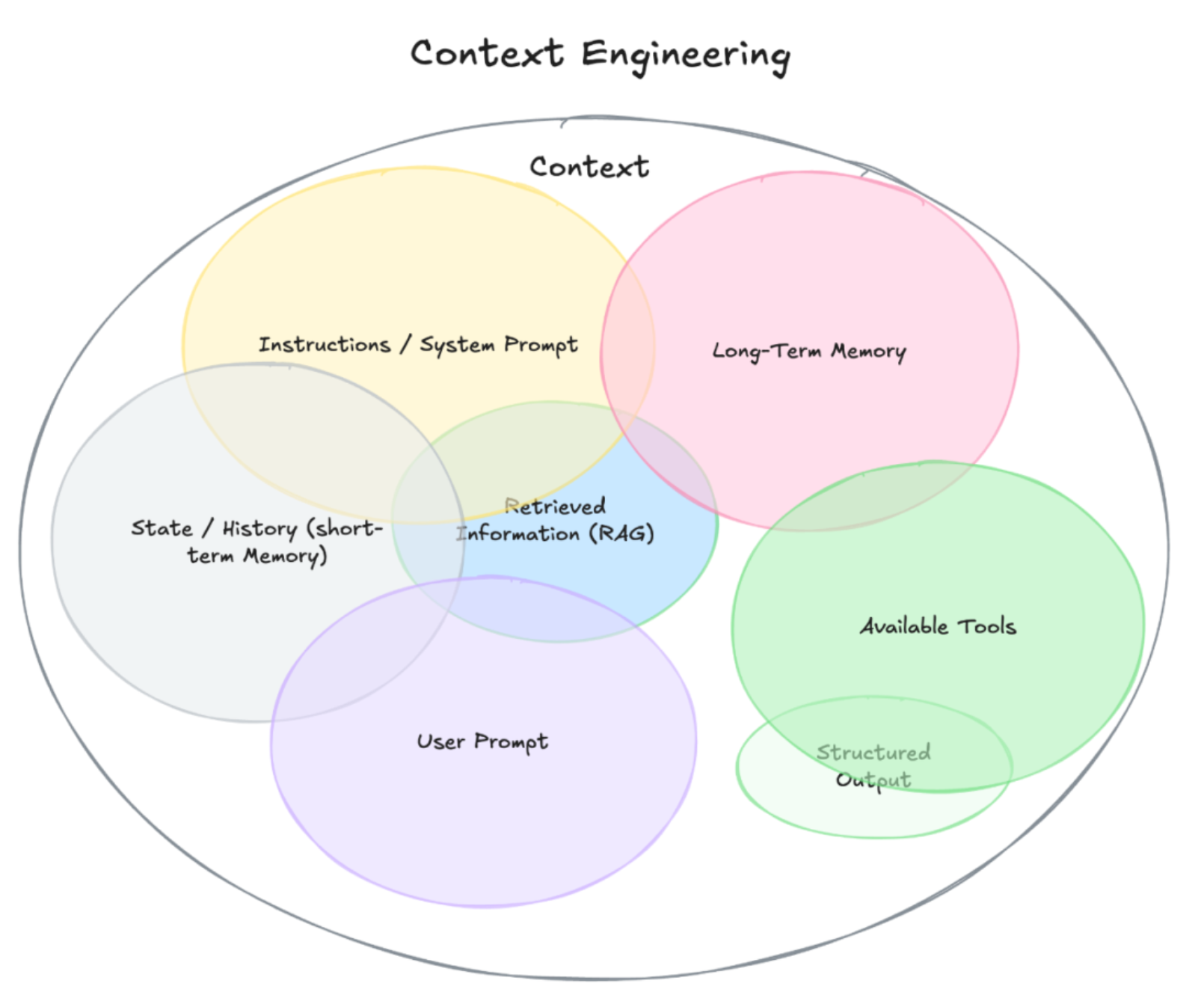
“Context”包含模型在生成回答之前,它所能看到的全部信息。不仅仅包含用户 | System的输入Prompt,还包括以下这些组成部分,它们共同构成了模型看到的Context:
- 系统指令(System Prompt):开场设定,告诉模型这次对话应该怎么表现。可以包含示例、规则等等。
- 用户输入:用户的提问或任务指令。
- 对话历史(短期记忆):本轮对话中模型和用户的所有来回问答内容。
- 长期记忆:跨会话保存的信息,比如用户偏好、过往项目的总结、或明确告诉模型要记住的事实。
- 外部检索信息(RAG):从文档、数据库或 API 获取的最新资料,用来辅助模型回答。
- 可用工具:模型可以调用的工具或函数说明。
- 结构化输出格式:指定模型回答的格式,如一个 JSON 对象。
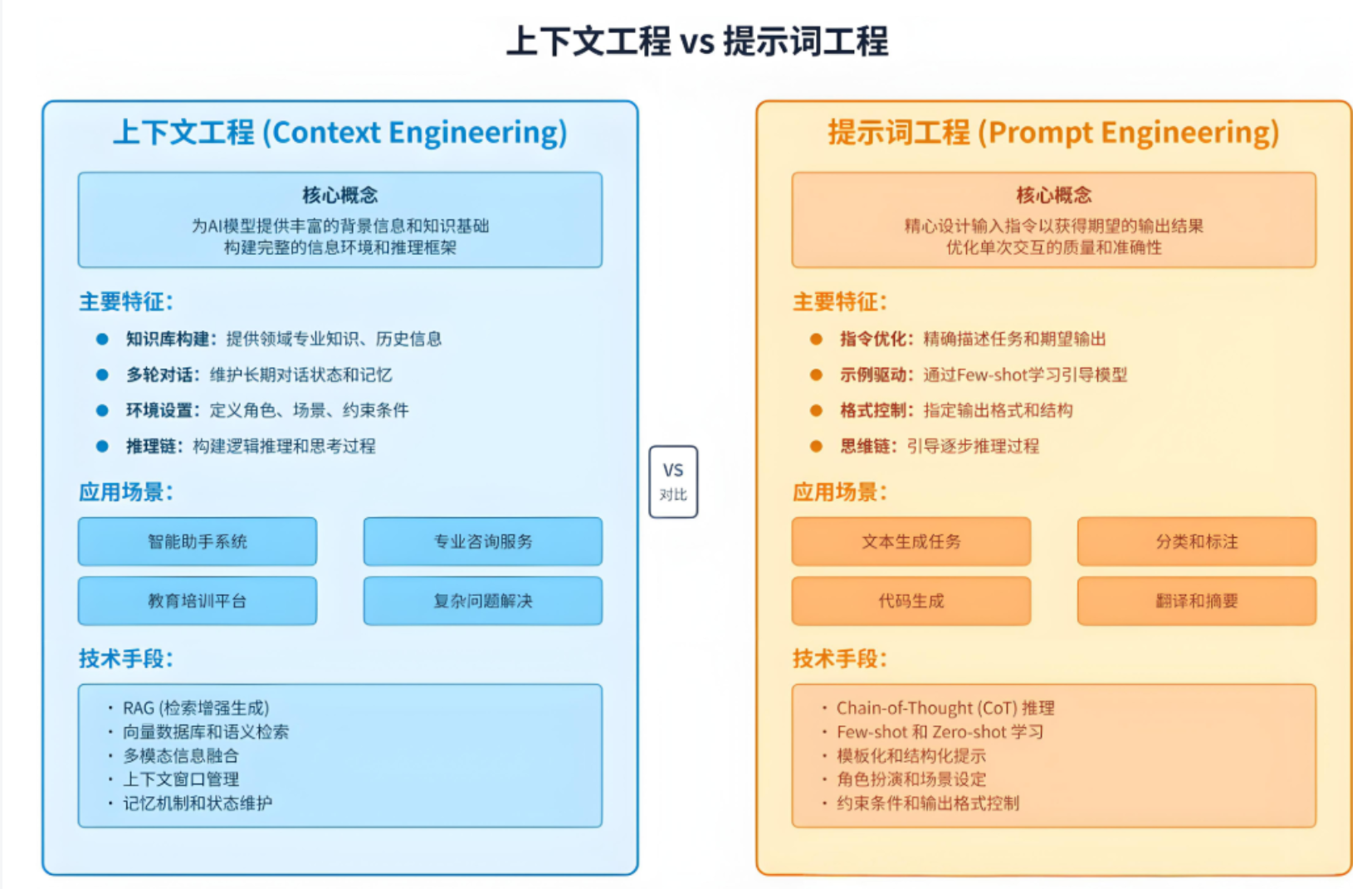
简单来说,Context Engineering就是给LLM提供”恰到好处”的背景信息,让它能准确理解任务并给出高质量的回答。它是提示词工程(Prompt Engineering)的进化和扩展,专注于如何更好地利用模型的上下文窗口。它教会我们如何与LLM“对话”,让LLM更好地理解我们的意图,以便生成更好、更符合人类预期的回答。
从“提示词工程”到“上下文工程”
主要区别:提示词工程专注于单次交互的优化和精确控制。上下文工程更注重长期知识积累和环境构建,其核心目标是通过动态管理和优化模型输入的上下文信息,提升模型的任务执行能力和输出质量。
如果提示词工程是写一段聪明的指令让模型尽可能给出好结果,那上下文工程做的事情要更复杂,上下文工程包含设计和构建一整套动态系统,确保在对的时间,把对的信息,用对的格式,喂给大模型,以更好地完成目标任务。
- 不是一句话,而是一个系统
- 按需生成,实时定制
- 关键在于“信息+工具”的时机与精度:模型输出质量好不好,核心是给它的东西准不准、够不够。
- 信息呈现方式也很重要:一堆乱七八糟的原始数据,远不如一个清晰的摘要;一段模糊的提示,不如一个结构明确的工具调用说明。
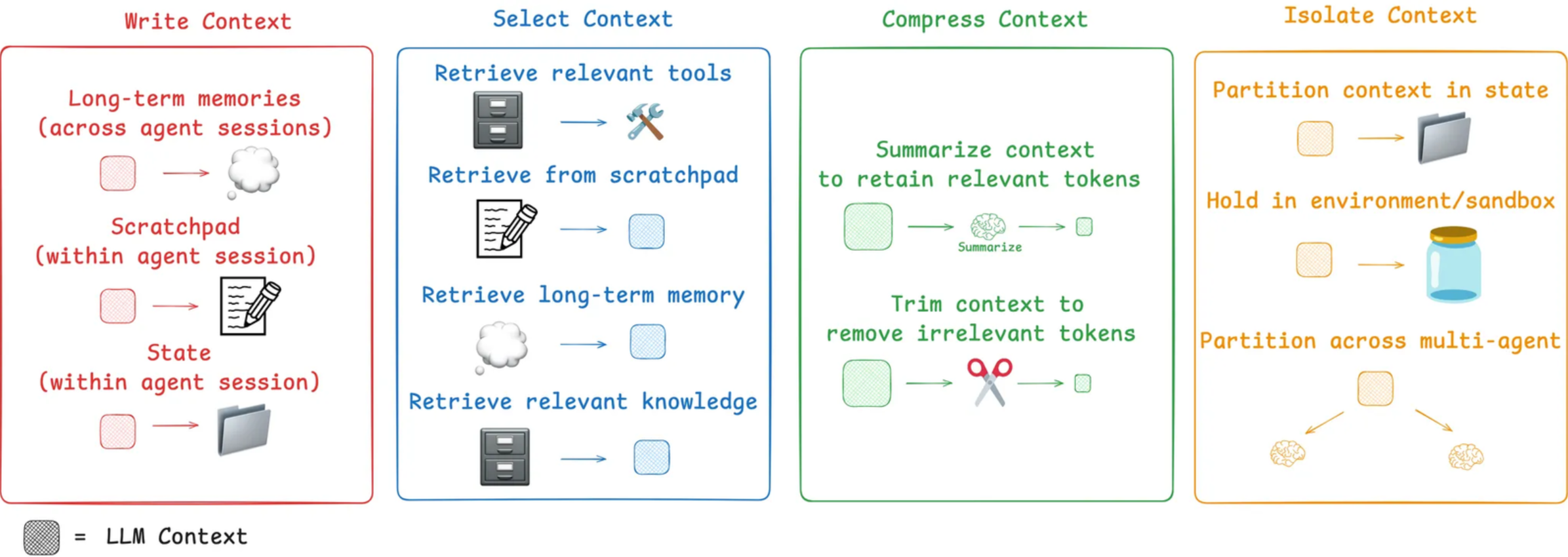
Agent的上下文工程的实现方法
可以分为四种方式:保存Context、选择Context、压缩Context、隔离Context
保存Context
保存一般由模型公司定义,可以根据模型支持的上下文长度看出该模型的记忆能力。
人类在解决任务时,可以通过做笔记,记住一些事情,以便将来完成相关任务。Agent也可以利用这些能力,通过其他方式将日后要使用的信息保存起来,可以存到内存、硬盘、数据库之内,在模型需要的时候再发给模型,核心理念是将信息保存在上下文窗口之外的地方,以便需要时可以取用。一个典型的例子是ChatGPT的记忆功能(长期记忆,跨会话保存的信息)。
选择Context
选择Context是指从海量的信息中选择出一部分与用户问题最相关的内容,并且把它们放在模型的Context中。一个好的选择策略是整个系统准确运行的基本保障。选择策略可以粗略分为静态选择和动态选择。静态相当于角色/Mask提示词,每次都固定调用;动态是模型根据输入的问题,主动寻找能用的内容(通常是RAG)或工具(最好用MCP)。
静态选择
把一些永远重要、必须遵守的信息在每一次请求时都全部放在Context里,就像是焊死给LLM的原则,无论用户问什么问题,都必须遵守这些要求。对于这些短小的信息,可以选择全都要,只要不撑爆上下文Context窗口就行,一般只占用少量的Token,例如系统提示词。
动态选择
选择与用户问题最相关的信息,把它放人Context里,例如从一大堆工具里选择用户需要的工具,或者是相关的向量信息,只把这些精心挑选的内容放入Context里,例如RAG动态选择最相关的内容再填充到提示词里。
压缩Context
压缩是在模型上下文超过限度后,穿插“总结”,实现上下文压缩,可以根据不同场景设计不同的压缩策略,始终保持重点。
Agent运行时会在Context里积累大量的历史消息,一般最占空间的是模型的输出文本和工具的执行结果,如果不做处理,这些历史消息会很快占满Context,常见的方法是压缩这些历史消息,可以通过设置阈值,例如达到窗口限制的90%就压缩一下。可以让LLM自己提取摘要信息,也可以自己设置压缩方法。
隔离Context
隔离是对复杂任务进行角色职能拆分,以实现各任务提示词与上下文的隔离,提高单一任务的执行质量(trae的角色/cursor rules/Claude.md 都是在做这个事情)。
不同模型之间的Context是相互隔离的(多见于Multi-agent之间),互不干扰。常见的架构是一个Lead Agent分派任务,给其他subagent执行具体任务。subagent是相互隔离互不影响的,Context内容也是相互隔离的。
精品文章
有关Context Engineering的知名文章,可以细品一下。