BERT模型
什么是BERT模型?
Bidirectional:双向的
This effect may be bidirectional, both positive and negative.
这一影响可能是双向的,既存在积极的影响,也隐含不利的一面
BERT(Bidirectional Encoder Representations from Transformers)是由 Google AI Language 团队在2018年提出的一种基于Transformer架构的预训练语言模型,通过在大量语料中进行训练,使模型能够理解自然语言中词语的含义、位置、语气和上下文意义,并能完成各种语言理解的任务。广泛应用于搜索引擎、问答系统、对话机器人等场景。
BERT 仅采用Transformer 架构中的编码器部分(原始 Transformer 中既有编码器,也有解码器),主要强调理解输入序列而不需要生成输出序列。
BERT的工作原理
BERT将输入的自然语言文本序列(句子或句对)转换成一系列的词向量。这些词向量通过多层Transformer编码器结构进行处理。在每一层中,自注意力机制都会帮助模型理解句子中每个词与其他词之间的关系,从而生成更具上下文信息的上下文嵌入(Contextual Embeddings)。这些上下文嵌入就是BERT对文本的深层理解。
BERT的特点
- 双向性(Bidirectional): BERT 同时考虑一个词左边和右边的上下文,不像传统模型(RNN or LSTM)只能单向理解(从左到右)。这使它能更好地理解词语在句子中的真正含义。具体实现方法为掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)。
- **掩码语言模型 (MLM)**: 在输入文本中随机遮盖(mask)掉15%的词语,然后让模型去预测这些被遮盖的词语是什么。这迫使模型在预测时必须充分理解上下文信息。
- **下一句预测 (NSP)**: 给定两句话,模型需要判断第二句话是否是第一句话的下一句。这有助于模型理解句子之间的关系,对于问答系统和文本蕴含等任务非常重要。
- 基于Transformer编码器架构: BERT采用
Transformer架构中的“编码器”部分。通过自注意力机制(Self-Attention Mechanism)能够高效地捕捉文本中长距离的依赖关系,这意味着它在处理长句子时也能很好地理解不同词语之间的关联。 - 预训练与微调(Pre-training and Fine-tuning): BERT的强大之处在于其“预训练-微调”的学习范式,BERT 首先在大规模语料上“通识学习”(预训练),再通过在特定任务上“专业训练”(微调),提高模型的通用性和性能。
- 预训练: BERT在海量的无标签文本数据(例如维基百科和书籍语料库)上进行大规模预训练,学习通用的语言表示。
- 微调: 针对特定的下游NLP任务(如情感分析、问答等),只需在预训练好的BERT模型基础上,添加一个简单的输出层,并用少量有标签的任务数据进行微调,就能达到非常好的效果。这种迁移学习的方式大大减少了特定任务所需的训练数据量和计算资源。
BERT基本结构
BERT 是基于 Transformer 模型架构,但只用其中的 Encoder(编码器) 部分。
- 12 层 Transformer Encoder(Base 版本)
- 每层都有:
- 自注意力机制(Self-Attention)
- 前馈神经网络
- 残差连接 + Layer Normalization
参数量:
- BERT Base:110M 参数(12 层,768 维隐向量)
- BERT Large:340M 参数(24 层,1024 维)
预训练阶段
用海量未标记的通用文本进行预训练,以学习上下文嵌入,让模型拥有普适的语言理解通识能力。
Masked Language Model (MLM)
随机遮住句子中一些词([MASK]),让模型预测它们。
例如:
输入:我今天[MASK]得很开心。
模型预测:[MASK] = 过
这使模型学会理解上下文语义。
Next Sentence Prediction (NSP)
- 判断两个句子是否是“相邻”的。
- 训练模型理解句子间的逻辑关系。
输入句子对:
- Sentence A: 他今天很开心。
- Sentence B: 他中了彩票。
→ 是连续句子 ➜ label = True
微调阶段
将预训练好的 BERT 拿去解决各种下游任务,如:
- 文本分类
- 情感分析
- 命名实体识别(NER)
- 句子相似度判断
- 问答系统(如 SQuAD)
只需要在特定任务上使用准备好的数据集进行微调即可,无需从头开始训练模型。与其他大模型的微调相似,只需要准备对应领域的高质量数据集即可。
BERT 的输入和输出长什么样?
输入:BERT 的输入是一种特殊格式的 token 序列,包括以下部分:
[CLS]:句首标志,用于整体句子分类- 句子A的 Token
[SEP]:句子分隔符- 句子B的 Token(如果有)
- Token Embedding + Position Embedding + Segment Embedding
例子:
句子对:“你是谁?” 和 “我是 AI。”
输入:[CLS] 你 是 谁 ? [SEP] 我 是 AI 。 [SEP]
输出:
每个输入 token 都对应一个向量(表示它的含义)
[CLS]对应的输出可以用于分类任务- 其他 token 的输出可以用于标注任务(如 NER)
BERT 的 Embedding 层(三种 Embedding 的组合)
BERT 的输入(Embedding模块)不是直接的词,而是由以下三个部分组成:
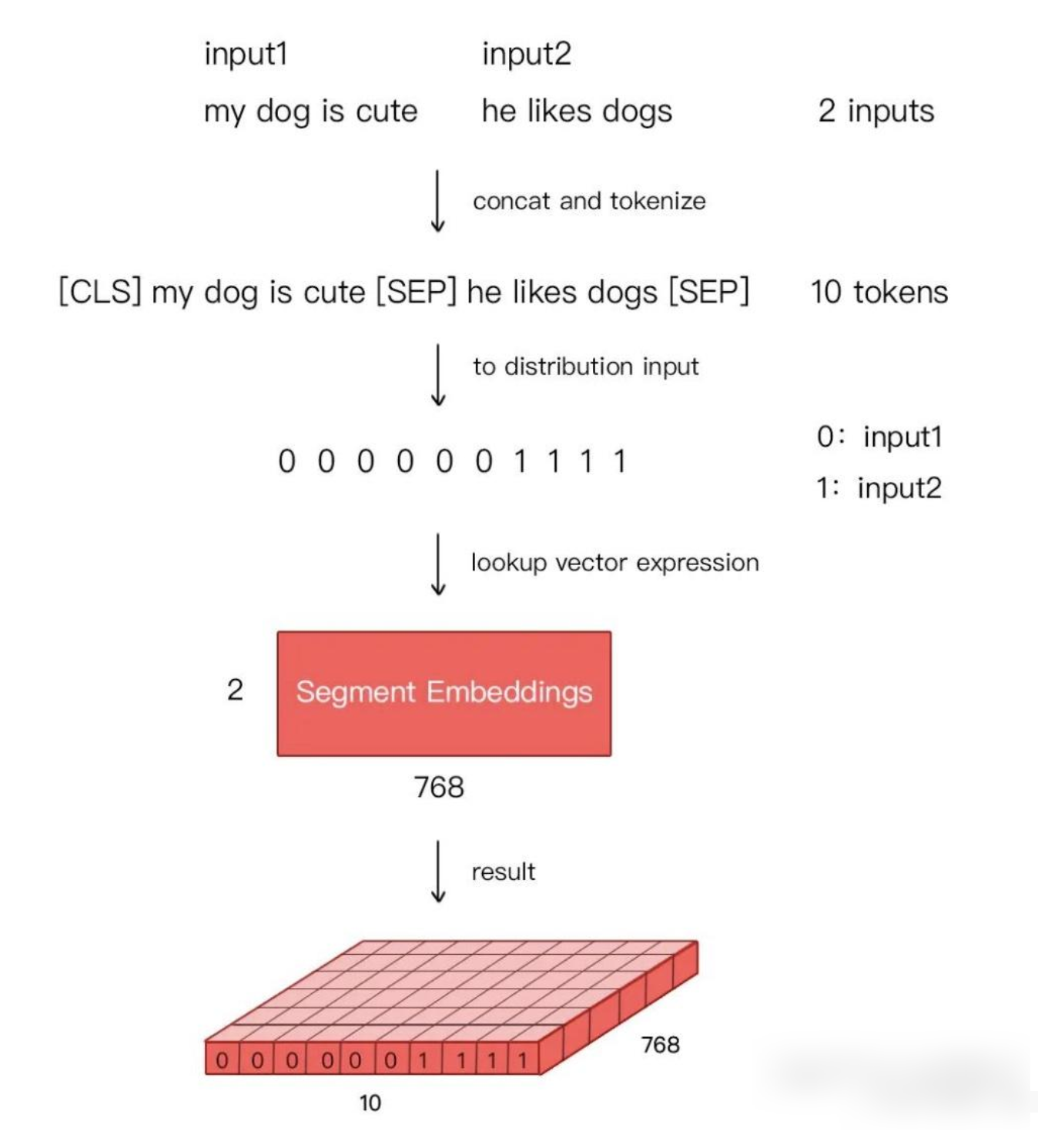
Token Embeddings:每个词的词嵌入, 输入文本中的每个单词或字符转换为一个固定维度的向量。Base版为768维,Large版为1024维。Segment Embeddings:用于区分句子 A 和句子 B 的段落嵌入, 单词或字符在句子中的位置信息。BERT中的位置嵌入是可学习的,它会随着模型的训练而更新,非固定的三角函数Position Embeddings:用于表示词在句子中的位置的位置嵌入,用于区分同一输入序列中不同句子的来源。对于多句输入,BERT会为每个句子分配一个不同的段编号,来区分它们。Segment Embeddings的取值通常是0和1,如果输入包含两个句子,通常第一个句子的token会被赋予全0的向量,第二个句子的token会被赋予全1的向量。
最终 BERT 的输入表示公式为:Embedding = Token Embedding + Position Embedding + Segment Embedding
| 嵌入类型 | 作用 |
|---|---|
| Token Embedding | 词向量:将词(或子词)映射为向量 |
| Position Embedding | 位置向量:表示这个词在句子中的位置 |
| Segment Embedding | 句子向量:表示这个词属于第一个句子还是第二个句子 |
Embedding 示例
假设有两个句子,用于句子对任务(如自然语言推理):
句子A: 我 爱 北京
句子B: 你 呢
第一步:构建 Token 序列
加入特殊 token [CLS] 和 [SEP],一共 8 个 Token。:
1 | [CLS] 我 爱 北京 [SEP] 你 呢 [SEP] |
第二步:三种嵌入分别长什么样?
1️⃣ Token Embedding
把每个词进行(其实是 WordPiece 子词)查表(词汇表),把每个词都变成一个向量(比如 768 维):
| Token | 向量表示(简化为维度) |
|---|---|
| [CLS] | 768维向量 A |
| 我 | 768维向量 B |
| 爱 | 768维向量 C |
| 北京 | 768维向量 D |
| [SEP] | 768维向量 E |
| 你 | 768维向量 F |
| 呢 | 768维向量 G |
| [SEP] | 768维向量 H |
2️⃣ Position Embedding
表示第几个词,用预定义的向量(和 Token Embedding 维度一样):
| 位置 | 向量表示(简化) |
|---|---|
| 0 | Pos_0 |
| 1 | Pos_1 |
| 2 | Pos_2 |
| 3 | Pos_3 |
| 4 | Pos_4 |
| 5 | Pos_5 |
| 6 | Pos_6 |
| 7 | Pos_7 |
3️⃣ Segment Embedding
表示句子属于哪一段:
| Token | 所属句子 | Segment Embedding |
|---|---|---|
| [CLS] | A | Segment_A |
| 我 | A | Segment_A |
| 爱 | A | Segment_A |
| 北京 | A | Segment_A |
| [SEP] | A | Segment_A |
| 你 | B | Segment_B |
| 呢 | B | Segment_B |
| [SEP] | B | Segment_B |
组合三种向量
对于每一个 Token(比如“我”):
1 | 最终输入向量 = |
这个过程对每一个词都执行一次,得到一个矩阵
1 | [ Token_0 ] → 768维向量 |
最终得到一个维度为:
1 | 输入向量形状: [句子长度=8, 每个词向量维度=768] |
这个向量就会送进 BERT 的 Encoder 层中。
BERT的应用场景
BERT的出现极大地推动了NLP领域的发展,被广泛应用于各种任务中,包括:
- 问答系统(Question Answering): 理解问题和给定文本,从中抽取答案。
- 情感分类(Sentiment Analysis): 判断文本表达的情感是积极、消极还是中性。
- 命名实体识别(Named Entity Recognition, NER): 识别文本中的人名、地名、组织机构名等实体。
- 文本分类(Text Classification): 将文本归类到预定义的类别,如新闻分类、垃圾邮件识别。
- 文本摘要(Text Summarization): 自动生成文章的简短摘要。
- 机器翻译(Machine Translation): 辅助或改进翻译质量。
- 语法纠错(Grammar Correction): 识别并纠正文本中的语法错误。
- 搜索引擎优化(Search Engine Optimization): 谷歌搜索已经将BERT模型应用到其搜索算法中,以更好地理解用户查询的意图