
DeepSeek模型原理与应用
DeepSeek-R1(深度思考)
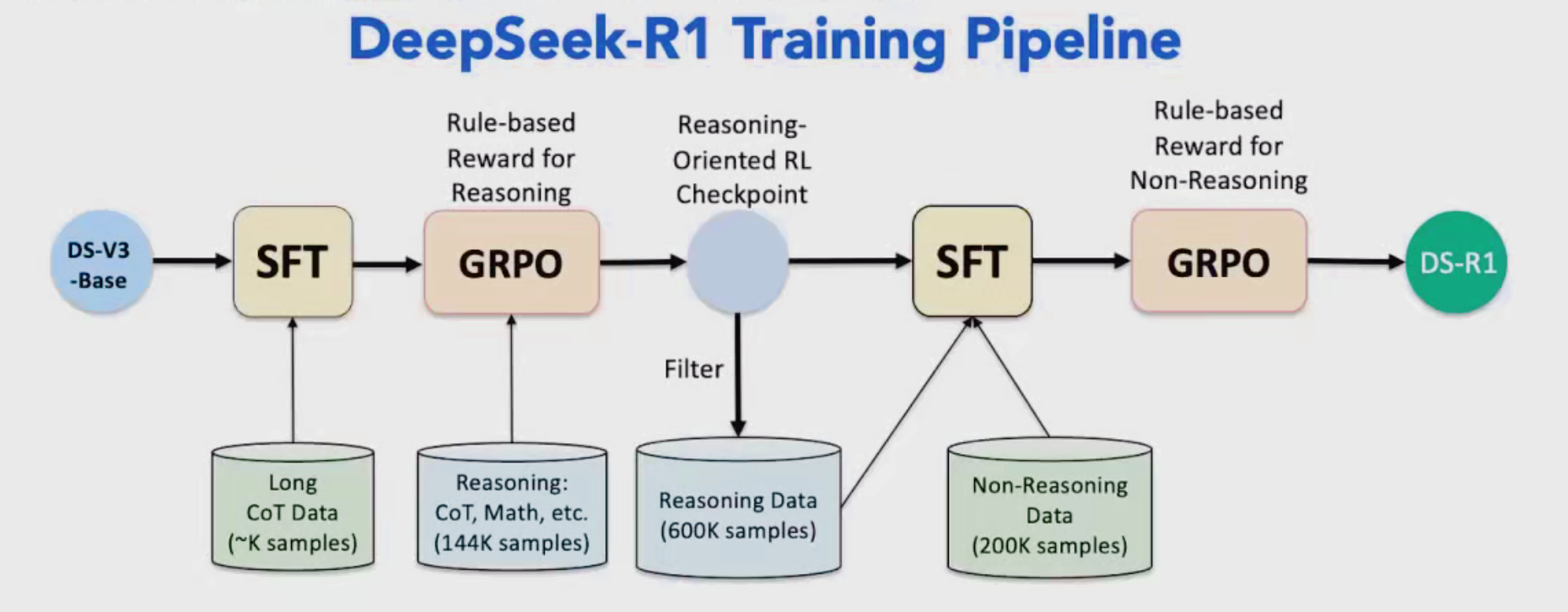
DeepSeek-R1的基础模型架构来自于DeepSeek-V3,可以说R1是具有推理(Reasoning)能力的V3,是以DeepSeek-V3作为基础模型的;
DeepSeek-R1完整版(671B):需要至少 350GB 显存/内存,适合专业服务器部署
思维链模型的原理与应用
CoT能减少模型幻觉问题,如果推理过程不合理,那么答案大概率也存在问题,就像是RAG回答问题时,它会给出依据,可以根据依据判断回答的问题是否正确;
思维链模型(Chain-of-Thought, CoT)是一种提示工程技术,引导大语言模型通过逐步推理解决问题,通过显式地展示模型的推理过程,提升其在复杂任务中的表现,模仿人类逻辑思考过程,将问题分解为多个步骤,逐步推导出答案,具备更强的可解释性和回答准确性;特别适用于复杂任务如数学、逻辑推理等。它不仅是R1模型的核心技术之一,更是推动大模型实现复杂推理能力的关键。
思维链:推理型大模型的核心
思维链的核心原理是“分而治之”策略
应用技术原理
分布提示设计
- 在编写大模型应用时,通过特定格式的提示(prompt)要求模型展示思考过程
- 使用关键字,例如“Let’s think step by step”触发逐步推理
- 支持零样本(Zero-shot)和少样本(Few-shot)两种模式
- 零样本(Zero-shot):模型在无特定任务训练数据的情况下,凭借预训练知识直接执行任务。
- 少样本(Few-shot):模型在少量(通常几例)任务特定示例的指导下,快速适应并执行任务。
中间状态生成
- 模型生成中间推理步骤作为文本
- 每个步骤作为后续推理的上下文继承(context)
- 通过自回归方式逐步生成结果内容提取
监督微调 (Supervised Fine-Tuning)
一个大模型(例如语言模型)在训练后具备强大的通用能力,但可能不完全适合某些特定的任务。微调会让模型更贴合某个目标或某个领域的特定知识。监督学习使用“输入-输出”对(如问题和正确答案)来进行学习。
SFT是一种在大型语言模型训练过程中广泛使用的技术。它发生在模型经过大规模无监督预训练之后。在预训练阶段,模型学习了海量的文本数据,掌握了通用的语言知识、语法和世界常识。但预训练的模型可能在特定任务或遵循特定指令方面表现不佳。SFT正是为了解决这个问题而诞生的。它利用标注好的数据集对预训练模型进行进一步的训练。这些数据集包含了特定的输入(如用户的问题或指令)以及期望的输出(如模型应该生成的回答格式或完成的任务)。通过在这些有监督的数据上进行训练,模型学会如何根据具体的指令或上下文产生符合要求的回应。如果将预训练比作让模型学习了大量的课本知识,那么SFT就像是针对某个具体的考试(特定任务)进行有针对性的习题训练,让模型更好地掌握如何应用所学知识来解答 specific problems。
Group Relative Policy Optimization(群组相对策略优化)
GRPO 指的是 Group Relative Policy Optimization(群组相对策略优化)。是一种用于训练大型语言模型(LLMs)的强化学习(Reinforcement Learning, RL)算法。它通过创新的群组相对策略优化方法,为大型语言模型在复杂任务上实现高性能表现、提高训练效率以及更好地与人类期望对齐提供了一种有效途径。GRPO 是一种比较新的强化学习算法,它在大型语言模型的后训练(post-training)阶段被用于进一步优化模型的性能,在处理复杂任务和 improving alignment(改善对齐)方面表现突出。
与传统的强化学习算法(如 PPO - Proximal Policy Optimization)不同,GRPO 的一个核心特点是它不依赖于一个单独的“价值函数”(value function)来估计预期奖励。相反,GRPO 采用了一种基于“群组相对”的方法来计算优势函数(advantage function),从而指导策略的更新。
具体来说,对于一个给定的输入(prompt),GRPO 会让模型生成一组(一个群组)不同的响应。然后,使用一个奖励模型(reward model)对这些响应进行评分。每个响应的“优势”不是根据一个独立的价值函数来计算,而是与其所在群组中其他响应的奖励进行比较,通常是与群组的平均奖励进行比较。这种相对比较的方式有助于更稳定和高效地更新模型的策略。
优势
GRPO被证明在提升模型处理复杂任务的能力方面非常有效,例如数学问题求解、代码生成以及需要复杂推理的场景。通过比较同一输入下不同生成结果的优劣,模型可以学习到更有效的解题思路或生成策略。相较于一些需要训练独立价值函数的 RL 算法,GRPO 通过移除价值函数的需求,显著降低了训练所需的内存和计算资源。这使得在计算资源有限的环境下训练和优化大型模型成为可能。
促进 emergent reasoning abilities (涌现推理能力): 一些研究表明,使用 GRPO 进行后训练有助于激发模型更强的推理能力,即使在预训练阶段模型可能没有针对此类能力的明确培训。
优化模型对齐: GRPO 可以用于进一步调整模型与特定的目标或人类偏好。通过设计合适的奖励函数来评估生成内容的质量、安全性和实用程度,引导模型生成更符合期望的输出。


