UNSW-NB15代码(来自github)
项目地址
项目发布于四年前,大概是2020年左右的代码,以
.ipynb的形式呈现实验过程和结果
github地址: IDS-UNSW-NB15
说明
实验使用的不是标准处理后的UNSW_NB15_testing-set.csv和UNSW_NB15_training-set.csv,而是使用下面四个csv文件,也是UNSW-NB15数据集官方提供的,只是比起处理好的训练集和测试集多了很多数据,而且大部分是良性数据,也就是说Normal数据占大部分,使用这几个数据集比处理好的训练集和测试集分类结果要好(因为良性数据占87%左右,怎么分类都能有不错的结果),但是使用下面的数据集会比原来提供的测试集和训练集更加不平衡
- UNSW-NB15_1.csv
- UNSW-NB15_2.csv
- UNSW-NB15_3.csv
- UNSW-NB15_4.csv
什么是EDA?
主要是看下数据集大概长什么样,以及简单处理一下
EDA(探索性数据分析,Exploratory Data Analysis)是一种数据分析方法,主要用于在建模和分析之前,帮助分析师和数据科学家了解数据的结构、特征和模式,从而提高模型的有效性和准确性。
主要包括但不限于如下几个方面:
- 数据总结:计算描述性统计量,如均值、中位数、标准差、分位数等
- 数据可视化:通过图表和可视化技术(如直方图、散点图、箱线图等)来直观展示数据特征和分布。
- 缺失值分析:检查数据集中是否存在缺失值,评估其对分析结果的影响,并决定如何处理这些缺失值
- 相关性分析:评估不同变量之间的关系,观察变量之间的关系强度和方向
- 异常值检测:识别数据中的异常值,这些值可能会影响模型的训练和预测性能。
- 数据分布检查:判断是否符合某种统计分布(如正态分布),这对于选择合适的模型和算法非常重要。
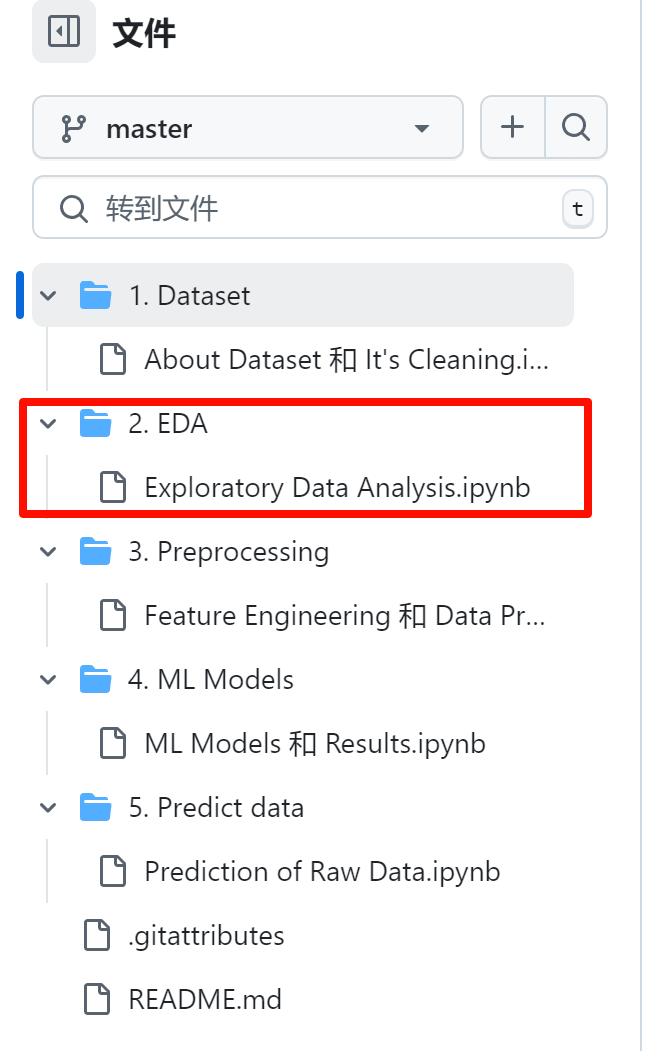
实验主要工作
1.Dataset主要工作如下
- 进行简单的数据清洗和预处理
- 填充空值,We don’t have “normal” values for “attack_cat”, so we must fill Null values with “normal”,
attack_cat列的normal值是NaN,把它填充为normal - 修正二进制列出现的异常值,把出现的2和4全部替换为1,Even though it’s a binary column, but there’re values like 2 and 4
- 把所有“-”值替换为None
- 保存简单处理后的数据为新的csv,训练集为
train_alldata_EDA.csv,测试集为train_alldata_EDA.csv
- 填充空值,We don’t have “normal” values for “attack_cat”, so we must fill Null values with “normal”,
- 数据集类型分布如下
1 | In Train: there are 0.8733599845222133 of class 0 and 0.12664001547778667 of class 1 |
2.EDA主要工作如下
- 生成属性热力图查看各属性的相关性
- 生成各种图片查看各属性的关联
3.Preprocessing主要工作如下
预处理
特征工程,在这一步把
'srcip', 'sport', 'dstip', 'dsport', 'attack_cat'这几列都删除了,所以后面得到95%以上的评估指标跟attack_cat这列没关系!!!标准化、one-hot编码,最后剩下197 columns
后面的不写了,太麻烦
实验结果
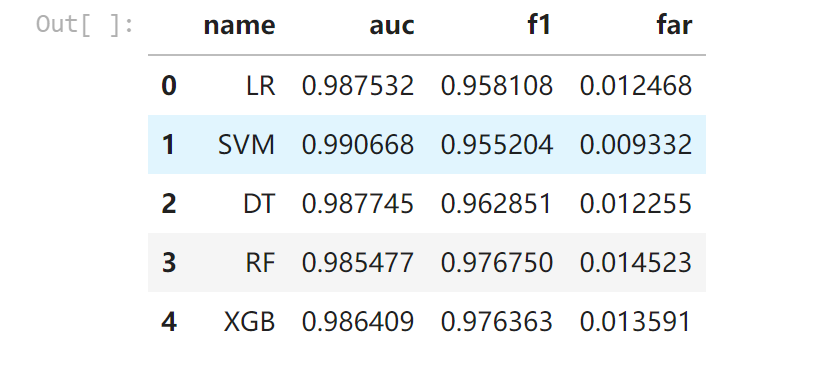
这个实验提供了多种Machine Learning的方法进行测试,
- Logistic Regression
- Linear SVC
- Decision Tree
- Random Forest
- GBDT( Gradient boosted decision tree)
但从实验结果看,每种试验方法的效果都很不错,有95%~98%的效果
但是我的论文打算使用的是深度学习方法,使用DNN或者CNN,先采用这个项目的实验方法来预处理数据,再把原来的机器学习方法换成深度学习方法看看效果如何。因为数据集太不平衡了,良性数据占了绝大部分,所以即使是效果不好,出来的结果也应该有90%以上,比预处理好的数据集好太多了,那个作死了也就91%左右,做差了才70%。
其他
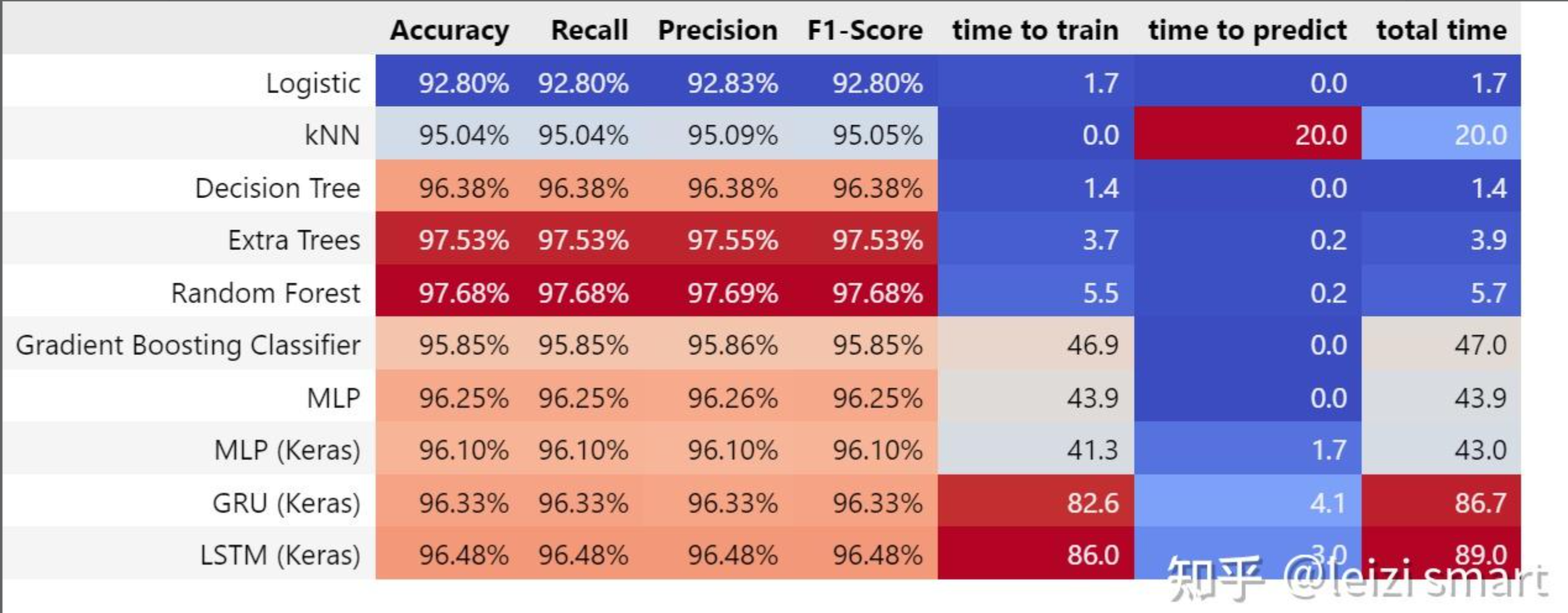
在知乎上还有一个关于UNSW-NB15数据集的实验, 知乎帖子 也是使用了ML或者DL的方法来处理数据集的,看起来结果也不错,但是!,他是直接从训练集里面划分出测试集的,没有使用别人弄好的测试集,所以看起来效果很好,其实已经过拟合了。
还有其他一些看起来很夸张的实验结果,什么accuracy、recall、F1-score全都是1.00或者0.9999..的,那些我怀疑他们都没有去掉attack_cat那一列,只要保留那一列,无论用什么方法都是100%的,因为这一列已经是标签列了
如果使用DNN或者CNN之后效果还能有95%左右的话,就可以使劲套方法增加模型复杂度了,原来的GSMOTE+AE+DNN(CNN)在CIC-IDS2017数据集反而会降低分类效果,直接使用DNN或者CNN效果都比套个AE要好,想用GSMOTE也用不上,一是one-hot编码后如果使用gsmote会使每一行新增的列都有小数产生,而不是固定只能为0或1值,还有就是数据集存在字符型数据处理起来很麻烦,另一个CIC-IDS2017数据集使用了gsmote,但是生成的数据也存在一些问题,全靠原来的数据集质量好才撑起99%的评估指标。
麻烦啊!