CIC-IDS2017使用DNN进行分类
数据集介绍
CIC-IDS2017数据集数据采集期从2017年7月3日星期一上午9点开始,到2017年7月7日星期五下午5点结束,共5天。星期一这天只包括正常的流量。该数据集实现的攻击包括暴力FTP、暴力SSH、DoS、Heartbleed、Web攻击、渗透、僵尸网络和DDoS。他们分别于周二、周三、周四和周五上午和下午被执行。
- 周一:只包含良性流量
- 周二:攻击+正常活动
- 上午:FTP-Patator
- 下午: SSH-Patator
周三:攻击+正常活动
- DoS / DDoS、Heartbleed
周四:攻击+正常活动
- 上午:Web Attack(Brute Force、XSS 、Sql Injection)
- 下午:渗透(Cool disk、Dropbox download)
周五:攻击+正常活动
- 上午:僵尸网络(Botnet ARES)
- 下午:Port Scan、DDoS LOIT
后续只使用周一、周二、周三、周五的数据进行实验 ,不包括周四,因为周四的种类又多每种类型的数量又少,麻烦
特征
数据集一共有79个特征,最后一列特征 Label是标签,BENIGN属于正常流量,其他值都是异常流量。所有特征值都是数值型(除了标签列Label),包含大量的0和负值,数据差异很大,要进行归一化处理。
数据集攻击类型分布情况
| 类型 | 数量 | 百分比 | Week Days |
|---|---|---|---|
| BENIGN | 2273097 | 80.300366 | Monday to Friday |
| DoS Hulk | 231073 | 8.162981 | Wednesday |
| PortScan | 158930 | 5.614427 | Friday |
| DDoS | 128027 | 4.522735 | Friday |
| DoS GoldenEye | 10293 | 0.363615 | Wednesday |
| FTP-Patator | 7938 | 0.280421 | Tuesday |
| SSH-Patator | 5897 | 0.208320 | Tuesday |
| DoS slowloris | 5796 | 0.204752 | Wednesday |
| DoS Slowhttptest | 5499 | 0.194260 | Wednesday |
| Bot | 1966 | 0.069452 | Friday |
| Web Attack � Brute Force | 1507 | 0.053237 | Thursday |
| Web Attack � XSS | 652 | 0.023033 | Thursday |
| Infiltration | 36 | 0.001272 | Thursday |
| Web Attack � Sql Injection | 21 | 0.000742 | Thursday |
| Heartbleed | 11 | 0.000389 | Wednesday |
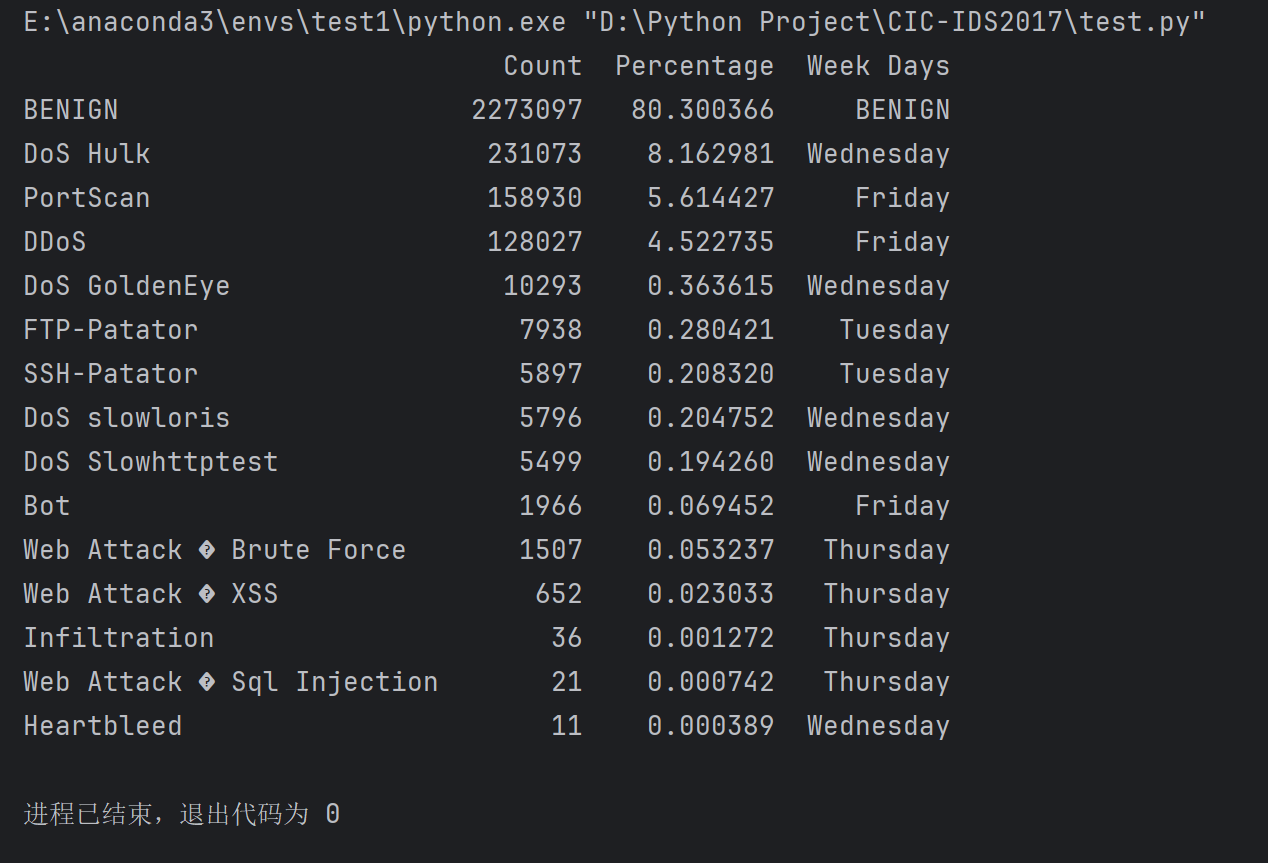
检查标签列Label分布情况代码
1 | import pandas as pd |
数据预处理
预处理流程如下
- 数据加载:加载周一、周二、周三和周五的子数据集,将它们合并为一个大的 DataFrame
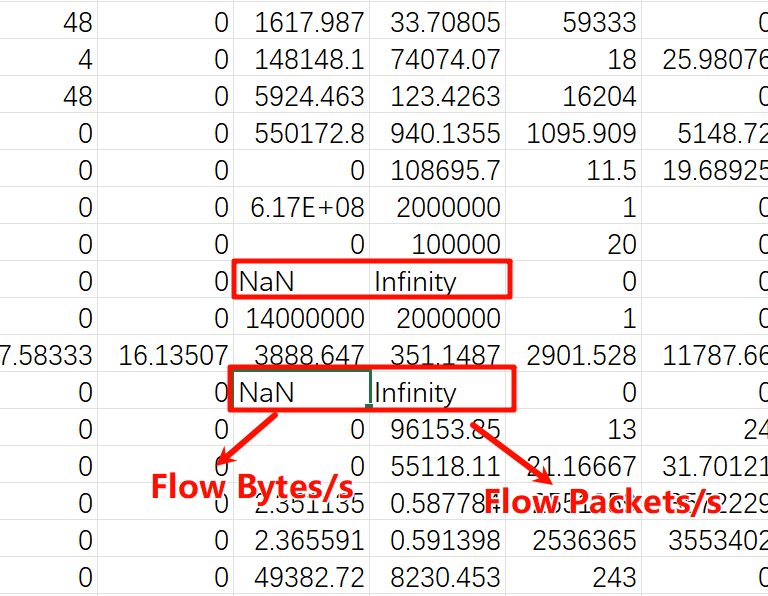
- 缺失值检查与替换
- 检查每列中的缺失值(NaN),统计数据集中总的缺失值比例
- 查找并替换数据集中出现的正无穷大和负无穷大值,将它们替换为
NaN
- 填充缺失值:将所有的
NaN替换为-999,便于后续删除(不替换为-1,因为数据集中真有一些值是-1,防止这些行被误删)。 - 删除多余的列:
- 删除99%以上的值都是0的列。
删除缺失值和无限值(填充为-1)超过30%的列。
- 删除存在缺失或无限值的行:去除所有存在
-999的行。 - 统计标签分布:统计并输出最后一列(标签列)的各类别数量和占比。
- 归一化:将整个DataFrame进行归一化,方便后续划分训练集和测试集
归一化与smote的先后顺序
不能先归一化在使用smote平衡数据集
在处理分类任务时,归一化和SMOTE的顺序通常是:
- 先进行SMOTE:先对训练集进行SMOTE采样来平衡样本。这样生成的合成样本会基于原始数据的特征值分布进行生成。
- 再进行归一化:SMOTE处理完后再对数据进行归一化。这样可以确保所有样本(包括原始和合成的样本)在同一归一化的范围内。
如果先归一化再使用SMOTE,生成的合成样本可能不会完全遵循归一化后的数据分布,导致数据表示不一致。因此,推荐先用SMOTE平衡样本,再对数据进行归一化处理。
def preprocessing()返回结果
return dataset,last_column_name
- dataset:预处理后的数据集,
已经完成归一化,但未划分训练集和测试集 - last_column_name:最后一列的名称
Label,可以不要
预处理代码
1 | import numpy as np |
划分训练集和测试集
按8:2的比例划分训练集和测试集,划分后的结果如下(未平衡数据集)
- x_train.shape : (1895400, 66) 训练集的X,1895400个样本,66个特征变量
- y_train.shape : (1895400,) 训练集的y,1895400个样本,1个标签列
- X_test.shape : (473850, 66) 测试集的X,473850个样本,66个特征变量
- y_test.shape : (473850,) 测试集的y,473850个样本,1个标签列
训练集
说明:因为没选用周四的数据,所以只有11种类型,而不是原来的15种
| 类型 | 样本数 | 比例 |
|---|---|---|
| BENIGN | 1451928 | 0.766027 |
| DoS Hulk | 184099 | 0.097129 |
| PortScan | 127043 | 0.067027 |
| DDoS | 102420 | 0.054036 |
| DoS GoldenEye | 8234 | 0.004344 |
| FTP-Patator | 6348 | 0.003349 |
| SSH-Patator | 4718 | 0.002489 |
| DoS slowloris | 4637 | 0.002446 |
| DoS Slowhttptest | 4399 | 0.002321 |
| Bot | 1565 | 0.000826 |
| Heartbleed | 9 | 0.000005 |
| 异常样本总数 | 443472 | 0.233972 |
测试集
| 类型 | 样本数 | 比例 |
|---|---|---|
| BENIGN | 362982 | 0.766027 |
| DoS Hulk | 46025 | 0.097130 |
| PortScan | 31761 | 0.067028 |
| DDoS | 25605 | 0.054036 |
| DoS GoldenEye | 2059 | 0.004345 |
| FTP-Patator | 1587 | 0.003349 |
| SSH-Patator | 1179 | 0.002488 |
| DoS slowloris | 1159 | 0.002446 |
| DoS Slowhttptest | 1100 | 0.002321 |
| Bot | 391 | 0.000825 |
| Heartbleed | 2 | 0.000004 |
| 异常样本总数 | 110,868 | 0.233972 |
平衡训练集
使用Gsmote平衡数据集代码
1 | def balance_training_set(X_train, y_train): |
模型评估指标
评估入侵检测系统性能时最常用的指标如下:
Accuracy
Precision
Recall
F-Measure
FAR/FPR

AE+DNN进行分类
代码如下
1 | import numpy as np |
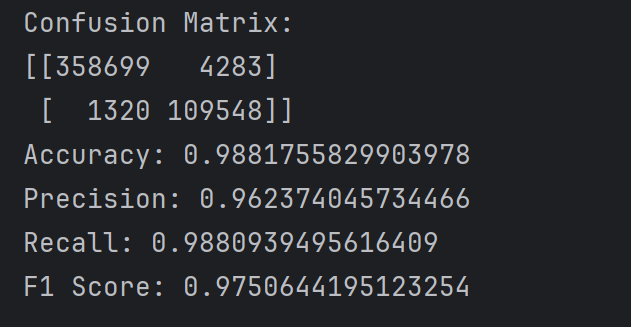
第一次
配置如下:
结果如下:
Confusion Matrix:
[[358699 4283]
[ 1320 109548]]
Accuracy: 0.9881755829903978
Precision: 0.962374045734466
Recall: 0.9880939495616409
F1 Score: 0.9750644195123254
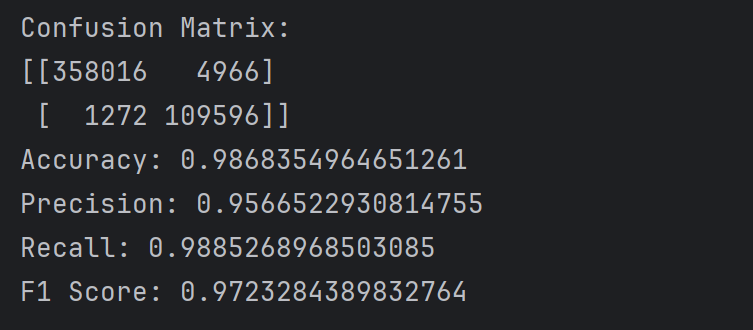
第二次
Confusion Matrix:
[[358016 4966]
[ 1272 109596]]
Accuracy: 0.9868354964651261
Precision: 0.9566522930814755
Recall: 0.9885268968503085
F1 Score: 0.9723284389832764
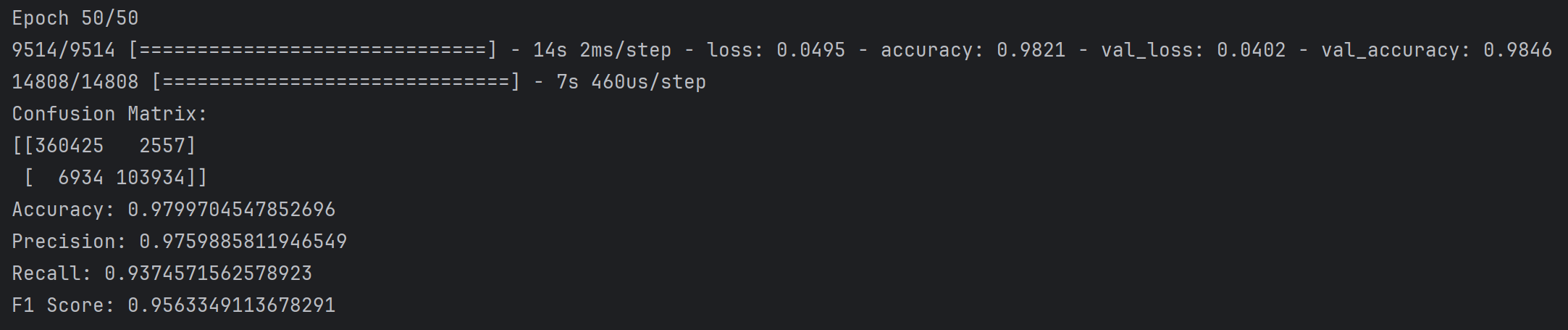
第三次
配置如下:
1 | def build_autoencoder(input_dim, encoding_dim): |
结果如下:
Confusion Matrix:
[[360425 2557]
[ 6934 103934]]
Accuracy: 0.9799704547852696
Precision: 0.9759885811946549
Recall: 0.9374571562578923
F1 Score: 0.9563349113678291
仅使用DNN
代码如下
1 | import numpy as np |
不使用AE, 用完AE就是负优化,垃圾,直接用DNN就能到99%,用完AE变97%,再看看能套什么别的
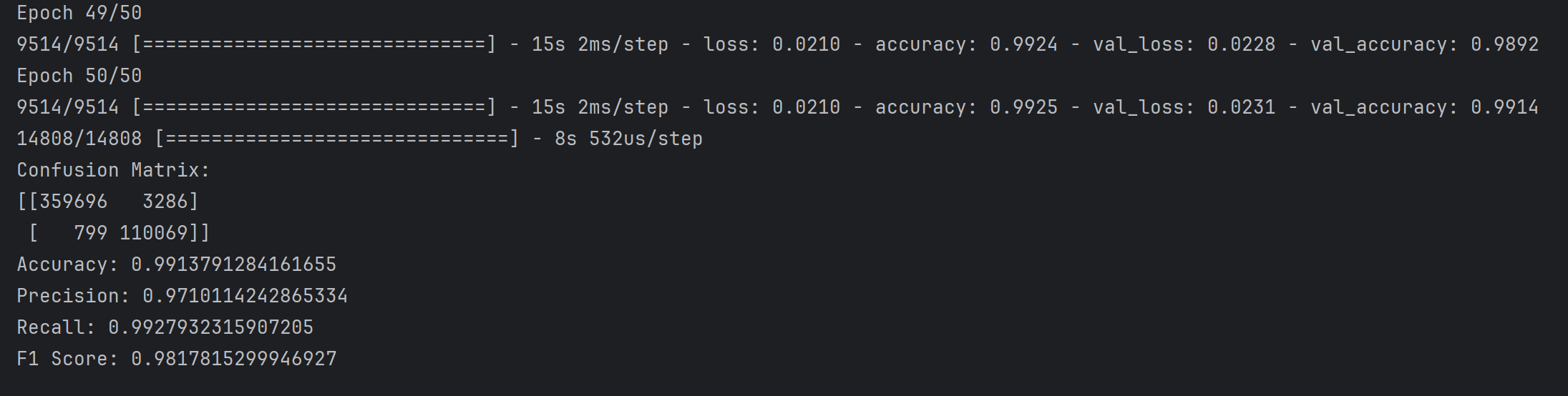
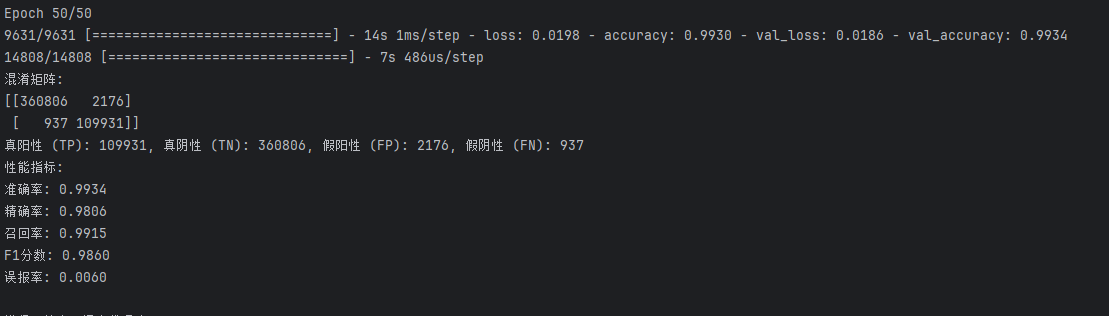
为什么只做了数据处理和平衡数据集就能达到如此夸张的识别率?
数据集中并没有像UNSW-NB15一样既有攻击类型,又有0-1标签列;之前使用UNSW-NB15划分数据集测试集后准确率接近100%是因为有attack_cat列没有去除,而标签列是label,所以导致数据泄露直接根据attack_cat就能识别出0或1,但是CIC-IDS2017不存在这种问题,为什么还是有如此夸张的识别率?跟平衡数据集有无关系?不适用Gsmote平衡数据集还能实现该结果吗?
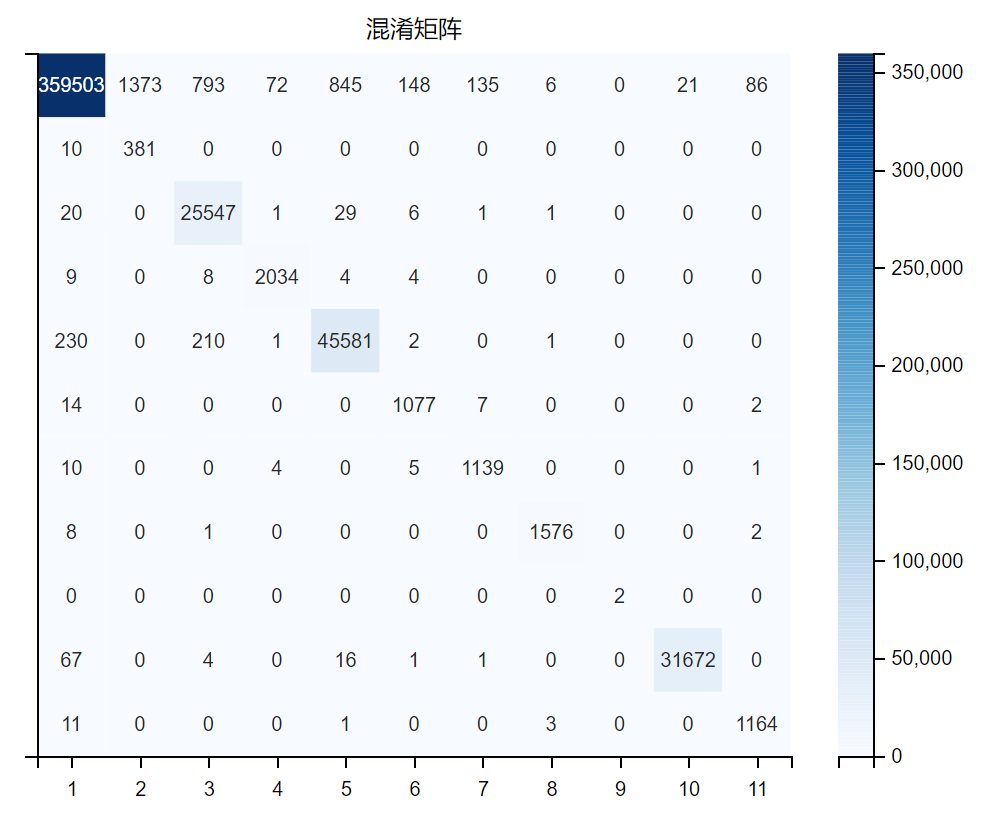
多分类
多分类第一次
进行多分类结果也很好
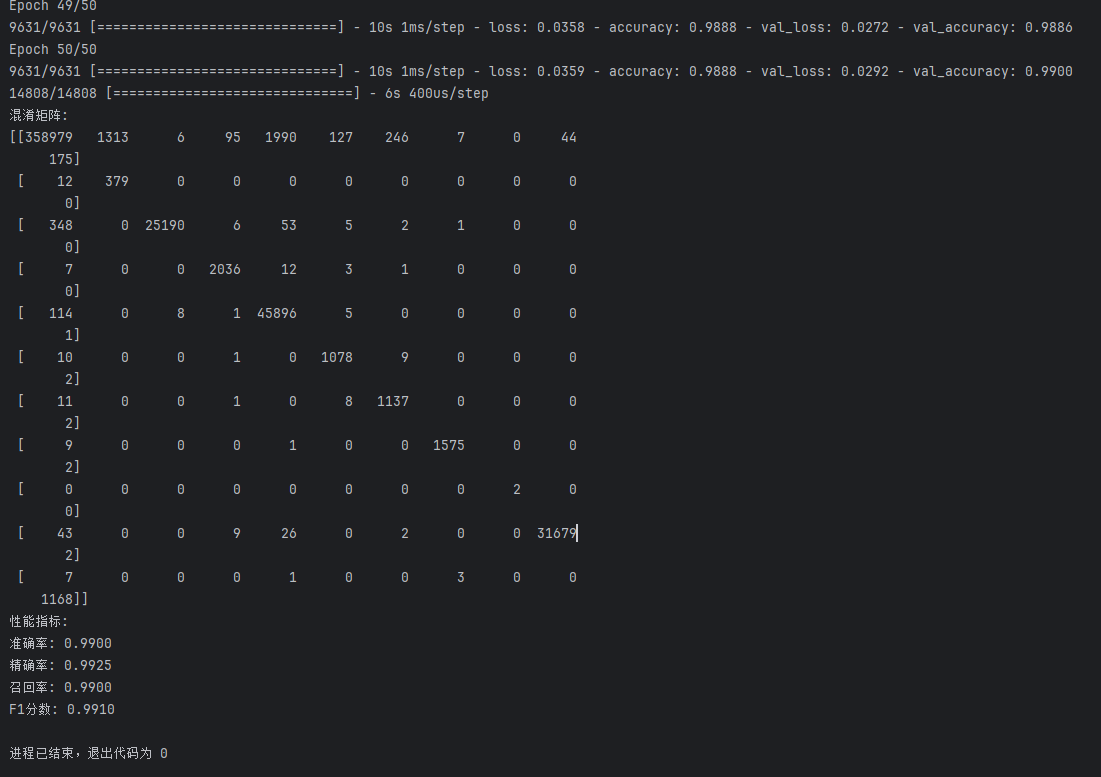
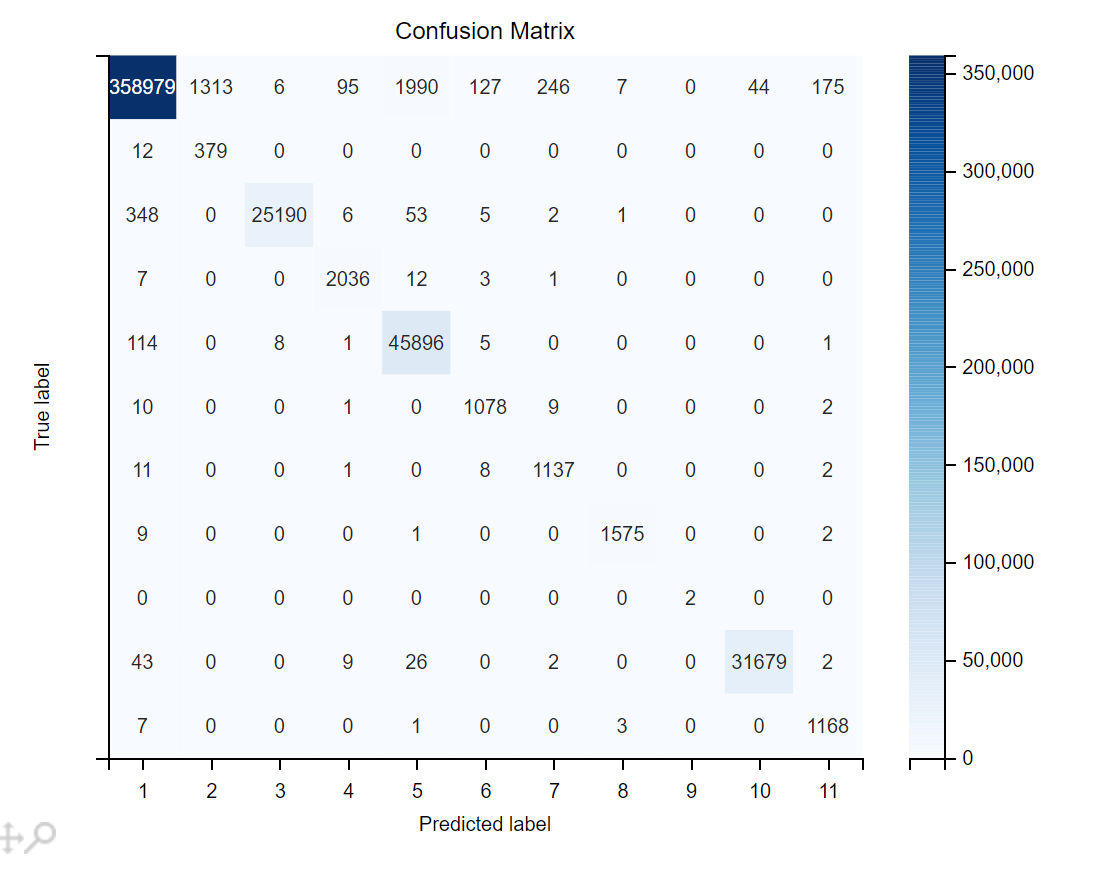
多分类第二次
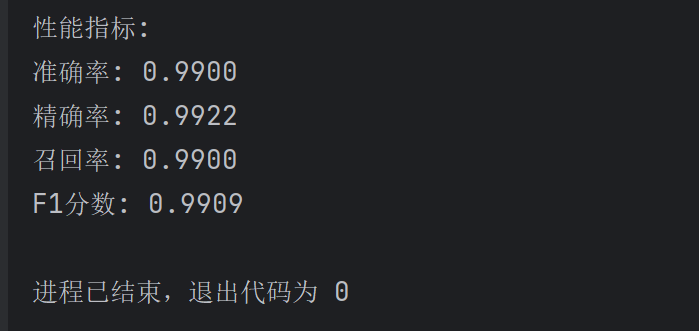
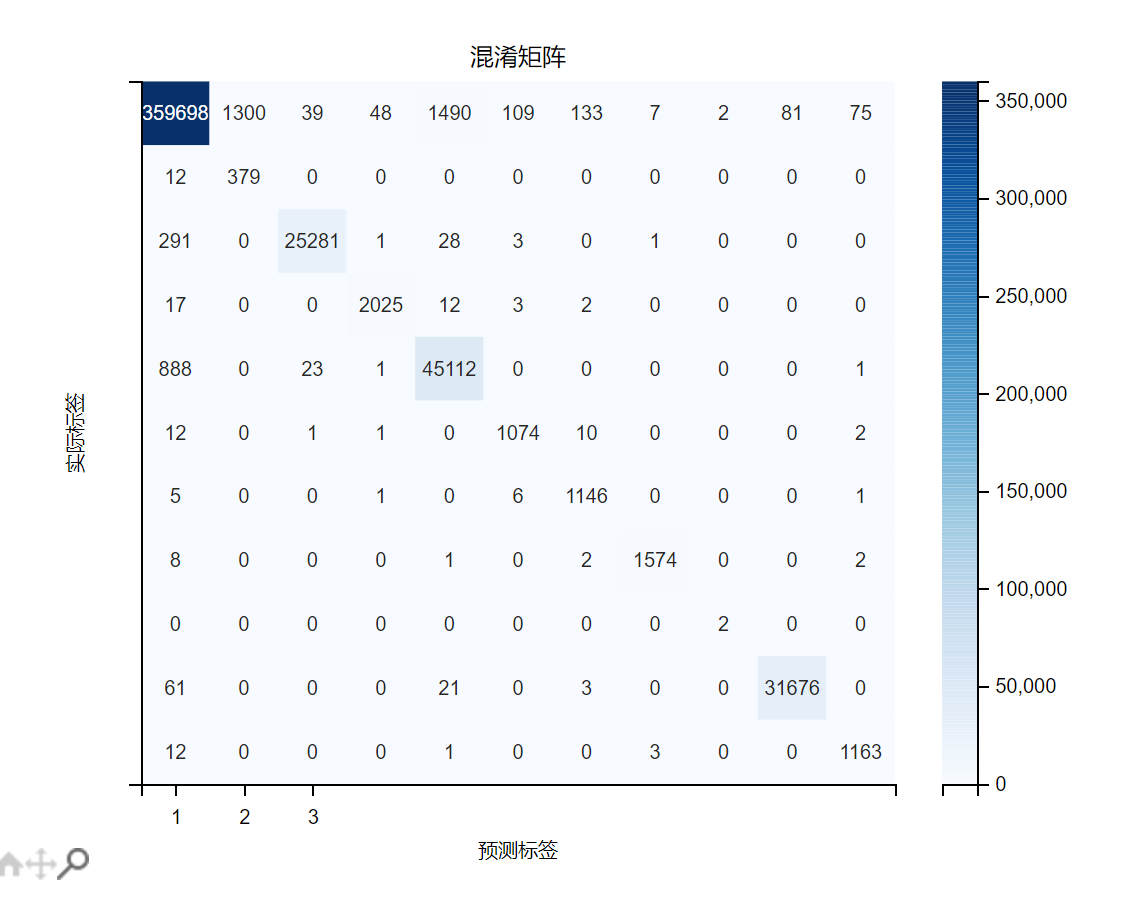
各类别分类结果
BENIGN
准确率Accuracy: 0.9894
精确率Precision: 0.9989
召回率Recall: 0.9904
F1分数: 0.9947
误报率FAR: 0.0034Bot
准确率Accuracy: 0.2160
精确率Precision: 0.2172
召回率Recall: 0.9744
F1分数: 0.3552
误报率FAR: 0.0029DDoS
准确率Accuracy: 0.9597
精确率Precision: 0.9618
召回率Recall: 0.9977
F1分数: 0.9794
误报率FAR: 0.0023DoS GoldenEye
准确率Accuracy: 0.9518
精确率Precision: 0.9631
召回率Recall: 0.9879
F1分数: 0.9753
误报率FAR: 0.0002DoS Hulk
准确率Accuracy: 0.9715
精确率Precision: 0.9807
召回率Recall: 0.9904
F1分数: 0.9855
误报率FAR: 0.0021DoS Slowhttptest
准确率Accuracy: 0.8507
精确率Precision: 0.8665
召回率Recall: 0.9791
F1分数: 0.9193
误报率FAR: 0.0004DoS slowloris
准确率Accuracy: 0.8741
精确率Precision: 0.8878
召回率Recall: 0.9827
F1分数: 0.9328
误报率FAR: 0.0003FTP-Patator
准确率Accuracy: 0.9862
精确率Precision: 0.9931
召回率Recall: 0.9931
F1分数: 0.9931
误报率FAR: 0.0000Heartbleed
准确率Accuracy: 1.0000
精确率Precision: 1.0000
召回率Recall: 1.0000
F1分数: 1.0000
误报率FAR: 0.0000PortScan
准确率Accuracy: 0.9965
精确率Precision: 0.9993
召回率Recall: 0.9972
F1分数: 0.9983
误报率FAR: 0.0000SSH-Patator
准确率Accuracy: 0.9165
精确率Precision: 0.9275
召回率Recall: 0.9873
F1分数: 0.9565
误报率FAR: 0.0002总体准确率: 0.9912